To kick off, I think it is important that we have a clear idea of what a change is and why change management is important.
“A change is defined by ITIL as the Addition, Modification or Removal of anything that could have an effect on IT services.” (ITIL v3 Foundation Handbook. TSO, 2009, pp. 92-93)
Now I would make one slight modification to this statement and replace IT Services with Business Services.
Why should we restrict the amazing work we are doing to just IT?
ITIL also tells us that “Change Management provides value by promptly evaluating and delivering the changes required by the business, and by minimizing the disruption and rework caused by failed changes.” (ITIL v3 Foundation Handbook. TSO, 2009, pp. 92-93)
Some of the key words that we should all keep a focus on are “Promptly” evaluating, “Minimizing” disruption to end users and also “Minimizing Rework” that is required when a change fails.
There are some common challenges that people have when looking at ITIL Change Management for the first time, or looking at improving their ITIL Change Management processes. Here are three of the main challenges that I see when discussing ITIL Change Management with clients:
Stuck with someone else’s mess
Many people fail before they even start because they are buried in a mess created before they arrived- either because of a failed attempt to get change management implemented, or just a complicated system that has always existed.
And as we know, many systems are just maintained because “That’s the way it’s always been done”.
Getting buy-in from the entire business is important. Having the business behind a push for better change management will enable you to wipe the slate clean and build something less complex and more targeted to the business.
Not sure where to start
Change management can be a big beast and can get people all bent out of shape knowing they will have to follow some sort of formalized process.
However, as we will see, there is no need for Change management to be as complex as people think it will be.
It’s Too Complex
Yes, this would have to be my personal number one bug bear with some change management processes.
But as we mentioned earlier ITIL tells us the change management should “Provide value by promptly evaluating and delivering the changes…..”
So if a change management process is taking to long or is an arduous process then we know we have it wrong.
Too many fingers in the pie
This is an oversimplification of this point.
What I’m trying to explain here is that many groups or sub groups that we work with do have set procedures that they use and are at varying levels of maturity and quite often these independent groups think they have it right and want to take care of it all themselves.
However, these processes are often independent of each other and can get in each other’s way or “rework” the same information or data several times.
Imagine if you will that ever car manufacturer had their own set of road rules. Individually these rules may work and may be a perfect procedure for that car manufacturer. That’s all well and good until we all start sharing the same road.
Then, we have chaos.
Even though everyone is following a set and tested procedure if we don’t take in to consideration all the other systems that we have within our business then we see conflicting issues and changes that were doomed to fail.
Specifically in IT, as our systems become ever more complex these issues occur on an all to frequent basis.
I’m sure everyone has an example of where a minor change to one system had a catastrophic outcome for some unrelated system that no one new about or had not considered.
Good ITIL change management can reduce the amount of time spent on unplanned work but it has to be effective.
Bad ITIL change management will just add an administration layer to the firefighting we always do.
This is both a waste of time and does not reduce the amount of unplanned work we have.
From what we have talked about so far there are some basic rules we can stick to that will help guide us to a good ITIL Change Management process.
Promptly is the key
If a process takes too long then no one is going to want to follow it. High risk issues are always going to take longer but there is no need to drag our feet where we don’t need to.
Low risk issues should be able to be speedily processed and maybe even automatically approved.
Which leads us to our next point,
Fit for Purpose
There is no need to bother your CAB with basic routine. If the CAB can clearly define what they require for a basic low risk change then make sure your process hits that and move on.
CAB have bigger fish to fry and more risk to deal with.
So why not have a simple process for Low risk changes. One Change Manager to review then do the change. SIMPLE!
How do we make sure that we capture these key points?
Standardization
Create templates where possible. Inject data we already know so people don’t have to guess at values or (like I am sure we have all seen) people just making up values.
It is more important to be able to get a consistent and complete result than it is to get the perfect result. Consistency allows us to report and see where we are doing well, and where we can improve.
More processes to make all this happen is NOT the solution. Often less is more when it comes to these processes.
We can all think of a change that we SHOULD do but never quite get around to it. How about rebooting a server? Depending on the server this could be low risk, minimal impact, not worth going to CAB over…. But should it be a change?
Remember a change is defined as “…the Addition, Modification or Removal of anything that could have an effect on IT services.”
Well why not have a change process that accepts that a low risk server can be rebooted without CAB approval, just so long as it is recorded?
Why not automate it?!
Of course none of this is any good if we don’t know the risk.
More specifically, Correct Risk.
So what is the best way to assign risk to our IT Services?
This is a big topic that usually takes many committees and sub committees, revisions, arguments, another committee and more arguments.
There is a much simpler way to assign risk to an IT service and you most probably have already done it. D.R.
We classify Disaster Recovery in most organisations. We have had the argument and we have spent the money to make sure those “Business Critical” systems have good quality D.R.
If you are like most organizations I’ve worked for you will have gone through the process of “What do we cover with DR?”
And we start by including EVERYTHING.
We then get the quote back from a vendor on what that DR solution would cost and we quickly write off half a dozen services without even thinking.
And again and again we go until we have a DR solution that covers our Business Critical systems.
Guess what? They are High risk.
Some systems we have internal HA solutions for. Maybe SCSM with 2 Management servers.
Not Critical…. We could live off paper and phone calls for a few hours or even days without it…. Let’s say medium risk.
Then we have everything else. Low risk.
Simple. Why over complicate it?
So all the theory in the world is all well and good but what are some real world examples? Well I’m glad you asked.
I wanted to show you a range of items that had a common theme but ranged in complexity and risk. That way I can demonstrate to you the way it can be done in the real world with a real scenario.
What better scenario than our own products.
However, there is no reason that these examples could not be easily translated to ANY system that you may have in your organisation.
Our first example is the Cireson Essentials Apps. Like Advanced Send E-mail, View Builder, and Tier Watcher.
These can be classified as “Low Risk” because only IT Analysts use them and IT Analysts can do their job without them, even though it would take more effort to do the job, they could still work.
Second is the Self Service portal. This effects more than just the IT Analysts and the impact on end users being able to view and update their Work Items and unable to use Self Service. But, all of this can still be done via phone or e-mail, although this will take longer and not be as simple for end users.
Finally, asset management is a high risk change that would happen to our system. Asset Management affects a wide range of systems and impacts SR’s as well as support details that analysts use.
In addition, the upgrade of AM is not a simple task. During the upgrade there are reports, cubes, management packs, DLL’s and PC client installs that are required.
So let’s take a look at what this looks like in the real world.
So when creating a change management process surely there are some simple steps we can follow to get the ball rolling.
Here is what I like to tell people are the 4 key pieces of a successful change management practice.
Less Process
Keeping the process as simple and as prompt as possible. This can be started by creating basic process templates for Low, Medium and high risk changes. There is always going to be exceptions that we have to add a little more process for but wherever possible stick to the standard three basic templates.
TEST!
The number 1 reason for failure of changes that I’ve ever been involved in is testing. There is nothing like the old “Worked fine in my lab… “ line.
The amount of rework or “Unplanned” work that stems from an untested change is huge and even just a little testing can catch big issues
Get the right people involved
We are not always experts in what a system is, what is does or how it should work.
How many times has your testing for an application package been to install it and if it installs without an error, it must be good?
What if when an end user logs on the whole thing crashes?
So even getting end users involved in your testing of minor changes can be a huge benefit.
And finally….
ITIL Review
So many places I see never have a formal ITIL review process.
These are critical for making sure the processes don’t stray from a standardized approach and that we know that all the obvious things are right and the whole thing is not going to blow up when we hit go.
Just reviewing the failures to find what went wrong is not enough.
It is also important that the changes that went right and fed back in to future decisions to avoid the ones that go wrong. This ITIL feedback should find it’s way back in to change templates AND base documentation for the systems so we keep all our processes up-to-date.
These don’t have to be long but these ITIL reviews can identify ways to make the process simpler, where a template can be created or where the CAB can be cut out of the picture entirely!
One fantastic question I had recently was “How many changes should we temple?”
This is a great question as many people think that templating everything they do is a waste of time. This is not the case.
If you have a change that you do on a recurring basis (not a once off) even if it only occurs once every six months or year, (In fact I’d argue especially if it is only once or twice a year) it is worth templating for two main reasons:
- Does anyone remember the correct process for the change?
Often a single person is responsible for a change and all the knowledge can be locked up in their head. By templating processes this way, we can ensure that the knowledge is available to everyone so if the original person is no longer available the change can still be a success. - Was the process successful last time we ran it and if not, what went wrong so we don’t do it again?
If you are only doing a change once or twice a year a template is a great way of making sure that lessons learnt are never lost and mistakes are worked out of the process.
A standard approach might include a set of standard activities that are carried across all risk levels, but we just keep adding to the process as we move up the risk profile. A basic template might look something like this:
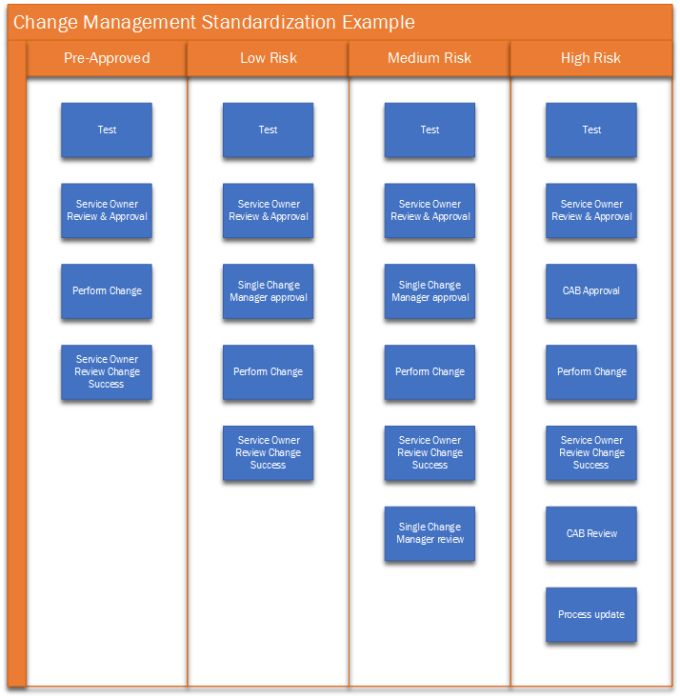
The above example is just an example. It is by no way prescriptive guidance that you should follow religiously, but more of a starting point. There is always going to be those changes that require more steps as the change is more complex. What is important is the basics are followed and a ITIL standard approach is followed to encompass the key points outlined in this article.
So to sum this all up in one paragraph:
- Prompt and Simple Process. Make ITIL quick and simple
- Standardize ALL changes to a simple set of rules and create templates
- Make sure your changes are fit for purpose. Only bother the CAB when you need to and have the right people involved
- Simple risk calculation (use disaster recovery plans if you don’t know where to start)
- TEST, TEST and RETEST!
- Review ITIL and document your changes to improve what you do
Ready to transform your SCSM experience? View all of the exciting apps Cireson has to offer.